Odi's astoundingly incomplete notes
New entriesCode
back | nextWeb Cruft
Rename an Oracle instance
Here is how to rename an Oracle instance.
Also change the instance name in
Also change the TNS name in network/admin/tnsnames.ora
If you also change the IP/hostname, don't forget to:
Also change the instance name in
/etc/oratab!Also change the TNS name in network/admin/tnsnames.ora
If you also change the IP/hostname, don't forget to:
- deconfigure the dbconsole
- shutdown database and listener
- /etc/hosts: change IP/hostname there
- $ORACLE_HOME/network/admin/tnsnames.ora and listener.ora
- startup database and listener
- configure the dbconsole again
Shrink your Oracle database
One thing, Oracle's Enterprise Manager Webapp miserably fails at is executing shrink recommendations that are given by its Automatic Segment Advisor. Here is a little procedure and log table for your SYS schema that does that well.
It shrinks tables and indexes when it saves more than 100MB. It works correctly for tables with function indexes and LOBs. Also for LOBs in securefile storage. It works even for a large number of objects. A failure in one object doesn't prevent work on other objects. It stops during office hours. And you get a nice log of what happened. Run it from a periodic job in your development instance and forget about it.
Interesting that 50 lines of code can do better than the EM.
It shrinks tables and indexes when it saves more than 100MB. It works correctly for tables with function indexes and LOBs. Also for LOBs in securefile storage. It works even for a large number of objects. A failure in one object doesn't prevent work on other objects. It stops during office hours. And you get a nice log of what happened. Run it from a periodic job in your development instance and forget about it.
Interesting that 50 lines of code can do better than the EM.
CREATE TABLE SHRINK_LOG (
DT DATE DEFAULT current_date NOT NULL,
TEXT VARCHAR2(4000)
);
CREATE OR REPLACE PROCEDURE SYS.SHRINK_DB IS
v_err VARCHAR2(4000);
v_memento VARCHAR2(4000);
BEGIN
delete from shrink_log where dt < current_date - 90;
insert into shrink_log (text) values ('starting');
commit;
for r in (SELECT segment_owner||'.'||segment_name as t, segment_owner as owner, segment_name as table_name, segment_type
FROM TABLE (DBMS_SPACE.asa_recommendations ('TRUE', 'FALSE', 'FALSE'))
where segment_type IN ('TABLE', 'INDEX')
and reclaimable_space > 100E6
order by segment_type desc, reclaimable_space asc) loop
-- stop during the day
if ((to_number(to_char(current_date, 'HH24')) >= 5) AND (to_number(to_char(current_date, 'HH24')) < 21)) then
insert into shrink_log (text) values ('exiting');
commit;
return;
end if;
begin
v_memento := NULL;
if r.segment_type='TABLE' then
for i in (SELECT di.owner||'.'||di.index_name as idx, ie.column_expression FROM dba_indexes di, DBA_IND_EXPRESSIONS ie
WHERE di.index_type LIKE 'FUNCTION-BASED%'
and di.owner=r.owner and di.table_name=r.table_name
and ie.index_owner=di.owner
and ie.index_name=di.index_name) loop
v_memento := v_memento || 'execute immediate ''create index '|| i.idx ||' on '|| r.t ||' ('|| i.column_expression ||')'';';
execute immediate 'drop index '|| i.idx;
end loop;
execute immediate 'alter table '|| r.t ||' enable row movement';
execute immediate 'alter table '|| r.t ||' shrink space cascade';
for l in (select l.column_name, l.tablespace_name
from dba_segments s, dba_lobs l
where s.segment_name = l.segment_name
and s.tablespace_name = l.tablespace_name
and s.owner = r.owner
and l.table_name = r.table_name
and s.segment_type='LOBSEGMENT'
and s.segment_subtype='SECUREFILE') loop
execute immediate 'ALTER TABLE '|| r.t ||' MOVE LOB('|| l.column_name ||') STORE AS (TABLESPACE '|| l.tablespace_name ||')';
end loop;
execute immediate 'alter table '|| r.t ||' disable row movement';
else
-- INDEX
execute immediate 'alter index '|| r.t ||' shrink space compact cascade';
end if;
if v_memento is not null then
execute immediate 'begin '|| v_memento ||' end';
end if;
-- rebuild any UNUSABLE indexes again
for r in (select * from dba_indexes where status!='VALID' and index_type='NORMAL' and partitioned='NO') loop
execute immediate 'alter index '|| r.owner ||'.'|| r.index_name ||' rebuild';
end loop;
insert into shrink_log (text) values (r.t||': OK');
exception
when others then
v_err := substr(SQLERRM, 1, 3900);
insert into shrink_log (text) values (r.t||': '||v_Err);
end;
commit;
end loop;
insert into shrink_log (text) values ('complete');
commit;
END SHRINK_DB;
/
Nice. Very Nice.
Hi guys,
Here is a good explanation how to reclaim the wasted space in a segment
http://dbpilot.net/2018/02/14/reclaiming-wasted-space-in-a-segment/
Here is a good explanation how to reclaim the wasted space in a segment
http://dbpilot.net/2018/02/14/reclaiming-wasted-space-in-a-segment/
git clone --reference with Cygwin
If you use git clone with the
Clever solution: edit the file and use a relative path (forward slashes). The path must be relative to
--reference option under Cygwin, the resulting repository will not work with native apps like Eclipse. The reason for that is that the .git/objects/info/alternates file contains an absolute Cygwin path (/cygdrive/c/...) which native apps can not resolve.Clever solution: edit the file and use a relative path (forward slashes). The path must be relative to
.git/objects, so use at least three levels up (../../../) as a prefix. Now the repository works with native apps and from the Cygwin command line.Crashes after updating microcode-data
Today Gentoo released the Intel Microcode update: sys-apps/microcode-data-20150121
After installation immediately a lot of applications crashed with the following log:
Some research revealed that this machine has an Intel Haswell CPU with buggy TSX. And the microcode update fixes this by effectively disabling TSX. This in itself is not a problem yet.
The most popular code that uses TSX is libpthread of glibc. And I had used an too old gcc version to compile glibc, with -march=native in CFLAGS. Unfortunately this gcc version enables TSX (hle, rtm) with the native optimizations enabled. So everything crashed at once.
The fix was to simply recompile glibc with gcc-4.8.4:
$
-march=core-avx2 -mcx16 -msahf -mmovbe -maes -mpclmul -mpopcnt -mabm -mno-lwp -mfma -mno-fma4 -mno-xop -mbmi -mbmi2 -mno-tbm -mavx -mavx2 -msse4.2 -msse4.1 -mlzcnt -mno-rtm -mno-hle -mrdrnd -mf16c -mfsgsbase -mno-rdseed -mno-prfchw -mno-adx -mfxsr -mxsave -mxsaveopt --param l1-cache-size=32 --param l1-cache-line-size=64 --param l2-cache-size=6144 -mtune=core-avx2 -fstack-protector
After installation immediately a lot of applications crashed with the following log:
kernel: traps: NetworkManager[1308] trap invalid opcode ip:7f8bba0b093a sp:7fffd40a22e8 error:0 in libpthread-2.20.so[7f8bba0a5000+16000]
Some research revealed that this machine has an Intel Haswell CPU with buggy TSX. And the microcode update fixes this by effectively disabling TSX. This in itself is not a problem yet.
The most popular code that uses TSX is libpthread of glibc. And I had used an too old gcc version to compile glibc, with -march=native in CFLAGS. Unfortunately this gcc version enables TSX (hle, rtm) with the native optimizations enabled. So everything crashed at once.
The fix was to simply recompile glibc with gcc-4.8.4:
# gcc-config -l [1] x86_64-pc-linux-gnu-4.8.4 * # emerge -1 glibcYou can check if gcc disables hle and rtm on your Haswell CPU correctly:
$
gcc -march=native -E -v - </dev/null 2>&1 | sed -n 's/.* -v - //p' -march=core-avx2 -mcx16 -msahf -mmovbe -maes -mpclmul -mpopcnt -mabm -mno-lwp -mfma -mno-fma4 -mno-xop -mbmi -mbmi2 -mno-tbm -mavx -mavx2 -msse4.2 -msse4.1 -mlzcnt -mno-rtm -mno-hle -mrdrnd -mf16c -mfsgsbase -mno-rdseed -mno-prfchw -mno-adx -mfxsr -mxsave -mxsaveopt --param l1-cache-size=32 --param l1-cache-line-size=64 --param l2-cache-size=6144 -mtune=core-avx2 -fstack-protector
Do not use Xerces, Xalan any more!
For years Java developers were used to require Apache Xerces and Xalan for their XML stuff. But those times are over. All this stuff is no longer necessary in modern JDKs (since at least 1.6 basically) and it does more harm than good to have these jars in your classpath or endorsed libs!
The problem is that the Internet is littered with references to Xerces and that even their Website is totally misleading. If you read that stuff you would believe that this is actually usefull code. But it isn't any more!
The first sentence on the website is "Welcome to the future!". But that's from at least 2010! The classes in xml-apis.jar are from 2009! All the code is build for JDK 1.3! Come on! Anybody who is still running 1.3 already has a lot of problems with the memory model / thread synchronization, let alone security issues! xml-apis contains ancient versions of JDK standard classes. For instance XMLStreamException doesn't even initialize the Exception's cause field, getting you nothing but incomplete stack traces.
I really wonder why this project can't get around to admit that it is effectively dead. They should really put a big fat warning on their website:
DO NOT USE THIS CODE ON MODERN JDKs. THIS IS FOR ANCIENT OR EXOTIC PLATFORMS ONLY, BASICALLY UNMAINTANED AND SUBJECT TO BITROT.
But no! All that 20 year old documentation still tells people to put that crap into the endorsed folder of the JDK where it will turn a perfectly good XML infrastructure into a jurassic version of itself.
These people don't realize how much worldwide developer time they are wasting by keeping this outdated website up!
Please also note that Xerces has security issues when exposed unconfigured to the Internet (webservices!), whereas JDK's built-in JAXP has sane defaults.
If your project still has Xerces, you should migrate away from it now. Chances are that you hard-coded some stuff on top of Xerces (like validation, feature strings, parser options, etc.). Use the modern JAXP equivalents!
The problem is that the Internet is littered with references to Xerces and that even their Website is totally misleading. If you read that stuff you would believe that this is actually usefull code. But it isn't any more!
The first sentence on the website is "Welcome to the future!". But that's from at least 2010! The classes in xml-apis.jar are from 2009! All the code is build for JDK 1.3! Come on! Anybody who is still running 1.3 already has a lot of problems with the memory model / thread synchronization, let alone security issues! xml-apis contains ancient versions of JDK standard classes. For instance XMLStreamException doesn't even initialize the Exception's cause field, getting you nothing but incomplete stack traces.
I really wonder why this project can't get around to admit that it is effectively dead. They should really put a big fat warning on their website:
DO NOT USE THIS CODE ON MODERN JDKs. THIS IS FOR ANCIENT OR EXOTIC PLATFORMS ONLY, BASICALLY UNMAINTANED AND SUBJECT TO BITROT.
But no! All that 20 year old documentation still tells people to put that crap into the endorsed folder of the JDK where it will turn a perfectly good XML infrastructure into a jurassic version of itself.
These people don't realize how much worldwide developer time they are wasting by keeping this outdated website up!
Please also note that Xerces has security issues when exposed unconfigured to the Internet (webservices!), whereas JDK's built-in JAXP has sane defaults.
If your project still has Xerces, you should migrate away from it now. Chances are that you hard-coded some stuff on top of Xerces (like validation, feature strings, parser options, etc.). Use the modern JAXP equivalents!
The "welcome to the future" statement at https://xerces.apache.org/xerces2-j/ is surprising indeed. It might make sense to contact those projects directly with your suggestions, if you haven't done that yet.
Already done: https://issues.apache.org/jira/browse/XERCESJ-1657
Guess what: nobody has ever answered.
This project is completely abandoned. Everybody has run away.
Guess what: nobody has ever answered.
This project is completely abandoned. Everybody has run away.
Sometimes I feel the same way about all these logging libraries out there, such as log4j, logback, slf4j.
JUL is already an extensible framework, instead of providing appenders and handlers, people started to create whole new frameworks. log4j should just have been allowed to die in the same way.
People tout the advantages of these frameworks in terms of isolated advantages (performance, asynchronicity, audit, etc, etc) , without ever mentioning they could have done the same by providing extensions under JUL.
And then there is the matter of none of them ever bothering unifying the configuration aspect, so even if you manage to put in a facade such as SLF4J, then it is still hell to unify the logging from different libraries using different frameworks.
JUL is already an extensible framework, instead of providing appenders and handlers, people started to create whole new frameworks. log4j should just have been allowed to die in the same way.
People tout the advantages of these frameworks in terms of isolated advantages (performance, asynchronicity, audit, etc, etc) , without ever mentioning they could have done the same by providing extensions under JUL.
And then there is the matter of none of them ever bothering unifying the configuration aspect, so even if you manage to put in a facade such as SLF4J, then it is still hell to unify the logging from different libraries using different frameworks.
I guess that what you are writing is only valid if one doesn't get hit by any of the (rare, but serious) bugs still present in the JDK-version of Xerces.
Example: https://stackoverflow.com/a/48843482
It is really sad, that we still have to bring Apache Xerces in as a dependency and JDK hasn't updated their code in so many years!
On the other hand: great that it is so easy to bring one's version. One line of Gradle did the job for me!
Example: https://stackoverflow.com/a/48843482
It is really sad, that we still have to bring Apache Xerces in as a dependency and JDK hasn't updated their code in so many years!
On the other hand: great that it is so easy to bring one's version. One line of Gradle did the job for me!
Can you believe it! After 8 years of playing dead man they managed to release 2.12.0. Clearly some people are still wasting their time beating a dead horse.
git: Dangerous default settings in Eclipse
When Eclipse imports a GIT repository, it sets some defaults that I can only describe as outright dangerous:
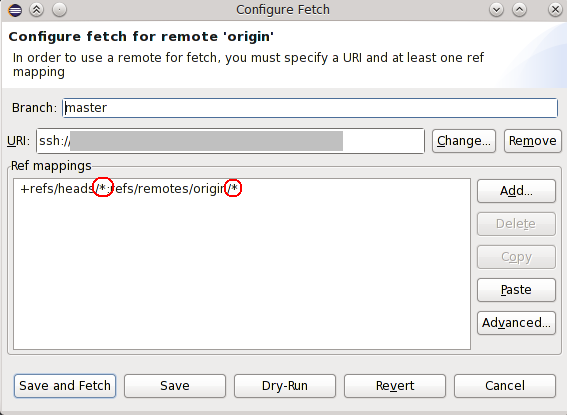
This setting means that each pull operation will fetch changes for all remote branches and merge them. This is totally unintuitive: it modifies stuff outside of the currently check-out branch. And it is the oposite of the command line git behaviour: you need explicitly specify if you wanted to fetch different branches (
If you happen to work with many work directories (one for each branch) that are based on the same git repository (git-new-workdir), that one click can get you into a lot of trouble if you are not ready to pull everywhere.
This setting means that each pull operation will fetch changes for all remote branches and merge them. This is totally unintuitive: it modifies stuff outside of the currently check-out branch. And it is the oposite of the command line git behaviour: you need explicitly specify if you wanted to fetch different branches (
git fetch origin somebranch:somebranch)If you happen to work with many work directories (one for each branch) that are based on the same git repository (git-new-workdir), that one click can get you into a lot of trouble if you are not ready to pull everywhere.
Gentoo to require initramfs
A Portage news item announces today that Gentoo is about to upgrade to udev-217. This upgrade will eliminate the userspace firmware loader. The change requires not only a kernel config change (CONFIG_FW_LOADER_USER_HELPER=N). It also may require an initramfs, if the kernel has drivers built-in that want to load firmware before the root filesystem is mounted. Examples of such drivers are: iwlwifi (Intel WiFi chips) or bnx2 (Broadcom NetXtreme II). Without userspace fw loading these drivers will fail to load their firmware. The standard solution to this problem is to use an initramfs.
A module-less initramfs is sufficient for that case (modules are built-in already), and it can easily be shared among different kernels.
Also if you need special drivers / setup to mount /, the initramfs must reside on a dedicated /boot partition. Typically for dm RAID, encrypted file systems, NFS root, root on other special devices, etc.
A module-less initramfs is sufficient for that case (modules are built-in already), and it can easily be shared among different kernels.
Also if you need special drivers / setup to mount /, the initramfs must reside on a dedicated /boot partition. Typically for dm RAID, encrypted file systems, NFS root, root on other special devices, etc.
interactive diff merge on the console
To quickly compare and merge files
ver1 and ver2 and save the result as merged:sdiff -s -o merged ver1 ver2It's the command that Gentoo's etc-update uses.
Gentoo fails to build dev-libs/boost-1.52.0-r7
If you get this:
Then put this into your
back
|
next
ln -f -s 'libboost_wave.so.1.52.0' 'stage/lib/libboost_wave.so' ...failed updating 1 target...
Then put this into your
/etc/portage/package.use:
# boost 1.52 is broken with current icu <dev-libs/boost-1.53 -icu
Just to ser how it is done. Nice work.